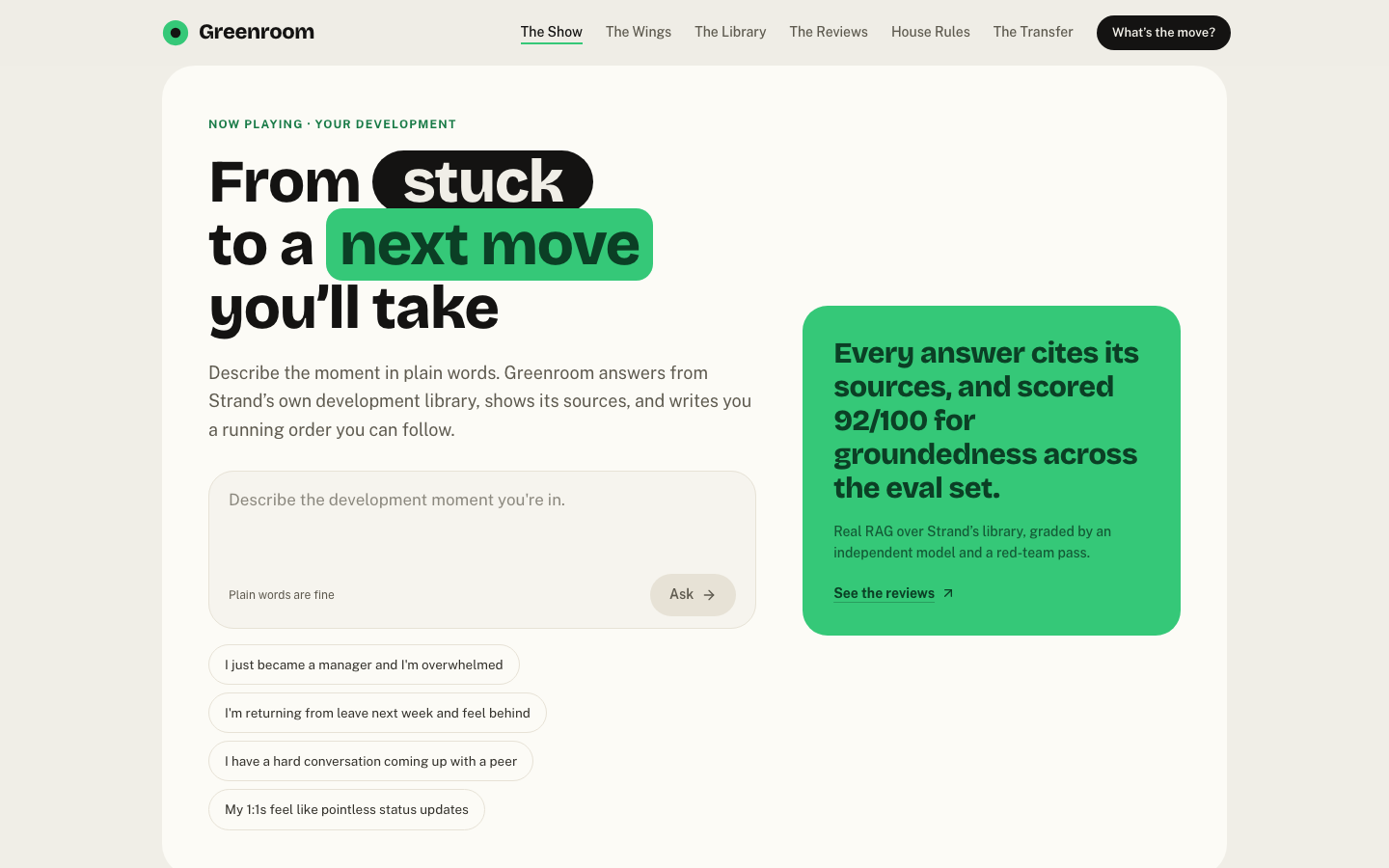
the live prototype
see it run.
The actual working app, embedded live. Open it full screen to ask a real question and watch it retrieve, cite, refuse the out-of-scope ones, and follow up.
greenroom-strand.netlify.app
open full screen ↗